Sono andato ulteriormente avanti con lo sviluppo della app creata settimana scorsa, e oltre a qualche fix posso annunciare che è possibile scaricare e utilizzare l’apk pronto. Basta guardare tra le release su repo github.
Ho qualche dubbio sull’opportunità di pubblicare sullo store ufficiale … dovrei informarmi su burocrazia e costi.
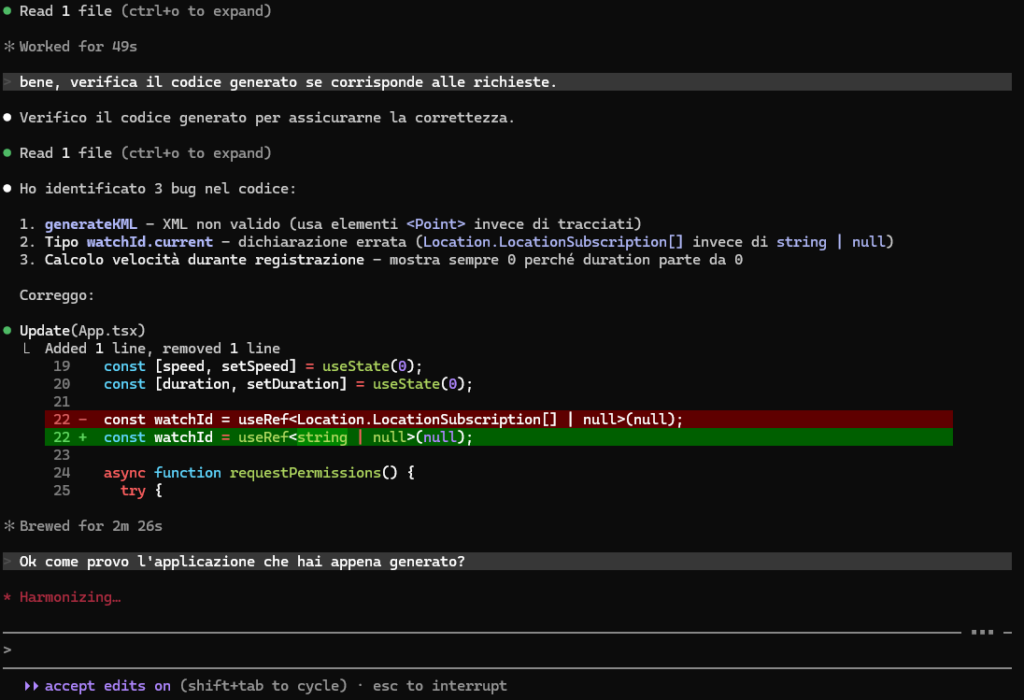
Continua la serie “Usiamo Claude Code a costo zero”, e questa volta ho unito la programmazione a un’altra mia passione: il volo.
L’Aero Club d’Italia (AECI) mette a disposizione un’applicazione desktop per simulare l’esame di conseguimento dell’attestato VDS (Volo da Diporto o Sportivo). Utile, certo – ma decisamente più comodo avere qualcosa in tasca, da usare anche lontano dalla scrivania. Non a caso esistono già alcune app per smartphone, tutte però a pagamento.
Ho voluto quindi fare un esperimento: quanto tempo ci vuole per replicare le funzionalità dell’app di AECI in formato mobile, usando un modello AI gratuito come strumento di sviluppo?
Il risultato
In circa una giornata di lavoro ho ottenuto un prototipo sostanzialmente funzionante. Lo strumento usato? Qwen 3 Plus, recentemente disponibile gratuitamente su OpenRouter, abbinato a Claude Code.
La qualità del modello è evidente: rispetto a Nemotron 3 Super rappresenta un netto passo avanti in termini di comprensione del contesto e qualità del codice generato. Poterlo usare gratuitamente sembra quasi troppo bello per essere vero – e probabilmente questa finestra non durerà a lungo. Consiglio di sfruttarla finché c’è.
La precedente esperienza con Qwen3.5 non aveva dato i risultati sperati. Nonostante ore di lavoro e feedback continui, il modello non è mai riuscito a produrre un’applicazione funzionante: regressioni cicliche ed errori difficilmente superabili con le capacità dello strumento hanno bloccato ogni progresso.
Ho voluto quindi riprovare con Nemotron-Cascade-2, ma le sue richieste hardware si sono rivelate eccessive per la mia macchina. Incuriosito comunque dall’ecosistema di modelli NVIDIA, ho scoperto che Nemotron 3 Super è disponibile gratuitamente su OpenRouter — e ho deciso di metterlo alla prova con lo stesso compito.
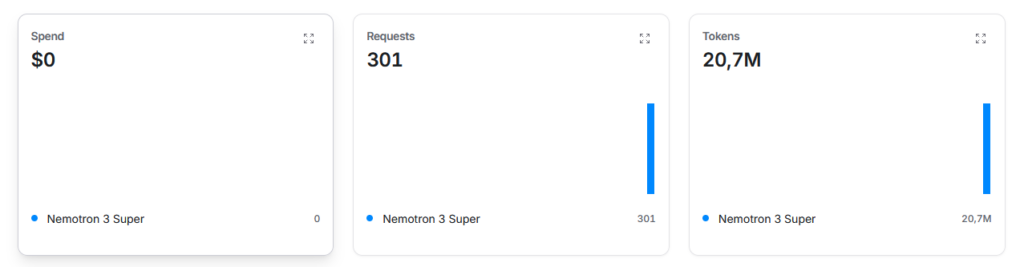
Quasi 21 milioni di token dopo, e con una spesa effettiva di 0$, l’applicazione non è ancora priva di bug. Eppure, in qualche modo, sembra più vicina a qualcosa di concreto rispetto a quanto ottenuto con Qwen3.5. Il dettaglio più incoraggiante? Non si è ancora bloccato su un errore irrisolvibile. Con qualche altra sessione di test e qualche milione di token in più, potrebbe davvero riuscire a chiudere il lavoro.
Resta però evidente una cosa: siamo ancora molto lontani dall’idea romantica di “mi faccio un’app semplice, senza scrivere una riga di codice, in pochi minuti”. Forse ci proverò anche con Claude Sonnet, se mi avanza qualche credito a fine mese.
Il progetto è pubblico: puoi scaricarlo e testarlo sul repository GitHub.
È possibile usare Claude Code con un modello locale — decisamente migliorato rispetto alle versioni precedenti — come Qwen3.5 per realizzare una piccola app Android senza scrivere una riga di codice?
L’impressione è che sì, si possa fare. Il modello configura tutto, scarica i framework, e dietro mio suggerimento si costruisce una lista di task da completare uno alla volta. Gli chiedo poi di riverificare il lavoro svolto, e in circa un quarto d’ora l’applicazione è pronta. In teoria.
Gli chiedo di riverificare tutto…
Il problema? Ha usato una versione del framework non ancora compatibile con Expo Go per i test diretti sul telefono. Da lì è partita una serie infinita di prompt di debug per abbassare la versione e aggiornare tutte le API interne, apparentemente diverse tra una release e l’altra.
Il risultato rimane comunque notevole, soprattutto considerando che tutto è generato da un modello da soli 9 miliardi di parametri, che gira su una scheda video nata per i videogiochi e tutt’altro che all’ultimo grido. Forse se non lo avessi forzato a passare dalla versione 55 alla 54 di React Native me la sarei cavata con meno litigi. Ma il limite vero sembra essere sempre lo stesso: la rifinitura del codice generato. O funziona subito, oppure ci vuole dieci volte il tempo che si impiegherebbe a scriverlo a mano.
Come piccolo aiuto ho agganciato Context7 come MCP server, per evitargli di allucinare le API dei framework — ma con successo solo parziale.
L’idea che l’AI ridurrà il nostro carico di lavoro è ormai un classico mantra: “automatizziamo, generiamo, ottimizziamo e finalmente lavoreremo di meno”. Peccato che, nella pratica, spesso accada esattamente il contrario: l’AI non riduce il lavoro, lo intensifica.
Cosa succede davvero in azienda
Uno studio recente su circa 200 dipendenti di una tech company ha mostrato che l’uso di strumenti generativi non ha tagliato ore o task, ma ha aumentato il ritmo, il numero di attività e il tempo complessivo speso al lavoro. Invece di sostituire compiti, l’AI li ha moltiplicati: chi prima delegava o rinunciava a certe attività ora le avvia da solo, spesso in parallelo, perché “tanto è facile”.
Il paradosso dell’efficienza
L’illusione è che, se un’attività richiede meno sforzo, si può fare di più senza problemi. In realtà, la somma di tanti piccoli compiti “semplificati” crea un flusso continuo di lavoro che aumenta la fatica cognitiva e il rischio di burnout. Il problema è che questo carico è spesso invisibile: non è un nuovo progetto ufficiale, ma una serie di micro‑attività auto‑generate, alimentate dall’entusiasmo iniziale per la sperimentazione con l’AI.
Perché serve una progettazione intenzionale
Se non si ridefiniscono ruoli, flussi e aspettative, l’AI diventa un acceleratore silenzioso di pressione, non uno strumento di liberazione. Per chi lavora con tecnologia e software, la lezione è chiara: non basta integrare modelli e tool; bisogna decidere cosa smettere di fare, quali decisioni restano umane e quali processi devono sparire, non solo diventare più veloci.
L’evoluzione dell’Intelligenza Artificiale nella programmazione ha suscitato grandi aspettative, ma la realtà è più complessa. Questo articolo esamina i limiti dell’AI nel generare codice, i tentativi di integrare agenti di programmazione e le sfide nella collaborazione tra umani e macchine.
I Limiti dell’AI nella Scrittura del Codice
Il modello mentale del developer è la comprensione profonda dell’architettura, della data flow e delle relazioni tra componenti di un sistema. Quando l’AI genera codice, questa comprensione viene oscurata, rendendo difficile mantenere la coerenza del sistema. Ad esempio, nel progetto dei test branch-specifici, l’AI ha introdotto funzionalità senza considerare l’impatto sull’intero codice, creando incoerenze. La fiducia nei confronti dell’AI si basa sull’incapacità di autovalutazione: l’AI sovrastima le proprie capacità, come nel caso del test su URL, dove ha ignorato regole fondamentali. Questo mancanza di introspezione rende difficoltoso valutare la qualità del codice generato. La collaborazione futura tra umani e AI dipende da un equilibrio: l’AI può assistere in compiti specifici, ma non sostituirà la capacità umana di comprendere il contesto globale. La fiducia deve essere costruita attraverso revisioni umane e una consapevolezza delle limitazioni dell’AI.
La Perdita del Modello Mentale e la Fiducia
La scomparsa del modello mentale del developer nel codice generato da AI rappresenta un problema profondo nel processo di sviluppo. Quando l’AI produce code chunks senza comprendere l’architettura globale del sistema, nasconde la complessità che un developer umano avrebbe chiarito. Ad esempio, un’implementazione di un feature senza tenere conto delle interazioni con altri moduli crea un’astrazione che rende difficile il mantenimento e l’estensione del sistema. Questo è particolarmente critico in contesti con alta coesione e bassa coupling, dove una modifica apparentemente marginale può scatenare errori di difficile tracciabilità. La fiducia nei confronti dell’AI si basa su un’autovalutazione che essa non possiede. Mentre un developer umano riconosce i propri limiti e corregge errori, l’AI tende a sovrastimare la qualità del proprio lavoro, ignorando edge cases o pratiche consolidate. Questo porta a code che funzionano in modo superficiale ma mancano di robustezza. La collaborazione futura tra umani e AI dovrà quindi bilanciare l’automazione con la supervisione critica, garantendo che l’AI agisca come strumento di supporto, non come sostituto. Solo integrando la capacità di riflessione umana con la velocità dell’AI si potranno sfruttare al meglio le potenzialità di entrambi.
Conclusioni
L’AI non sostituirà i programmatori, ma agirà come strumento ausiliario. La collaborazione tra umani e macchine richiede una critica consapevole, con il focus su task specifici come testing e refactoring. Per ulteriori dettagli: Why agents DO NOT write most of our code – a reality check.
Nel mondo dell’intelligenza artificiale, i grandi modelli linguistici (LLM) hanno rivoluzionato il modo in cui interagiamo con la tecnologia. Tuttavia, il loro potenziale si svela solo quando vengono addestrati in modo mirato a specifiche applicazioni. Ecco che entra in gioco LLaMA Factory, un progetto open source che semplifica e ottimizza il processo di fine-tuning di oltre 100 modelli LLM e VLM (Vision-Language Models). Con il suo approccio unificato, LLaMA Factory si presenta come una soluzione versatile per sviluppatori, ricercatori e aziende che desiderano sfruttare al massimo le capacità dei modelli linguistici.
Cos’è LLaMA Factory?
LLaMA Factory è un framework open source progettato per semplificare e accelerare il processo di fine-tuning di modelli linguistici di grandi dimensioni. Sviluppato da un team di esperti, il progetto è stato presentato al ACL 2024 e si distingue per la sua capacità di supportare una vasta gamma di modelli, da LLaMA a Qwen, da Mistral a DeepSeek, e non solo. LLaMA Factory unifica diverse metodologie di addestramento, come il fine-tuning supervisionato, la modellazione delle ricompense e le tecniche di ottimizzazione avanzate, rendendo il processo di personalizzazione dei modelli più accessibile e efficiente.
Il framework è progettato per adattarsi a diverse esigenze: che si tratti di un’azienda che desidera creare un modello specializzato per il supporto clienti o di un ricercatore che vuole esplorare nuove tecnologie, LLaMA Factory offre strumenti flessibili e potenti.
Le Caratteristiche Chiave di LLaMA Factory
LLaMA Factory si distingue per una serie di funzionalità che lo rendono unico nel panorama degli strumenti per il fine-tuning dei modelli LLM. Ecco le sue principali caratteristiche:
Supporto per 100+ Modelli LLM e VLM
LLaMA Factory supporta una vasta gamma di modelli, tra cui LLaMA, LLaVA, Mistral, Qwen, DeepSeek, Phi, GLM, e molti altri. Questo rende il framework adatto a diverse applicazioni, da compiti di comprensione del linguaggio a compiti multimediali come l’analisi di immagini o video.
Metodi di Addestramento Integrati
Il framework include diverse tecniche di fine-tuning, tra cui:
Fine-tuning supervisionato
Modellazione delle ricompense (Reward Modeling)
PPO (Proximal Policy Optimization)
DPO (Direct Preference Optimization)
KTO (Knowledge Transfer Optimization)
ORPO (Optimizing Reward with Preference Optimization)
Questi metodi permettono di adattare i modelli a specifiche esigenze, come la generazione di testi, il ragionamento logico o l’interazione con utenti.
Ottimizzazione delle Risorse
LLaMA Factory supporta diverse strategie per ridurre il carico computazionale, come:
LoRA (Low-Rank Adaptation)
QLoRA (Quantized LORA)
GaLore, BAdam, APOLLO, DoRA
Queste tecniche permettono di addestrare modelli su hardware meno potente, riducendo i costi e il tempo di elaborazione.
Strumenti per la Gestione degli Esperimenti
Il framework integra strumenti per il monitoraggio e la gestione degli esperimenti, come:
LlamaBoard
TensorBoard
WandB (Weights & Biases)
MLflow
Questi strumenti aiutano a tracciare i progressi, confrontare i risultati e migliorare la produttività del processo di addestramento.
Interfaccia Utente e CLI Zero-Code
LLaMA Factory offre un’interfaccia web (LlamaBoard) e un CLI (Command Line Interface) che permettono di eseguire il fine-tuning senza codice, rendendo il processo accessibile anche a chi non ha esperienza avanzata in programmazione.
Supporto per Inference Rapida
Il framework include strumenti per l’inference veloce, come l’API OpenAI-style e il supporto per vLLM, che permettono di deployare i modelli in modo efficiente.
Perché Scegliere LLaMA Factory?
LLaMA Factory si distingue per la sua flessibilità, potenza e facilità d’uso. Ecco i vantaggi principali:
Unificazione di Metodi e Modelli: Riduce la complessità di gestire diversi framework e modelli, concentrando l’attenzione sulle esigenze specifiche del progetto.
Ottimizzazione delle Risorse: Grazie alle tecniche di quantizzazione e adattamento a basso rango, permette di addestrare modelli su hardware limitato.
Supporto per Task Complessi: Dalla comprensione del linguaggio ai compiti multimediali, LLaMA Factory è adatto a qualsiasi applicazione.
Community e Documentazione: Il progetto ha una documentazione completa e una comunità attiva, con blog, tutorial e esempi pronti all’uso.
Come Iniziare con LLaMA Factory
LLaMA Factory è facile da installare e usare, grazie alla sua struttura modulare e alla documentazione dettagliata. Ecco i passaggi principali per iniziare:
Installazione
Il framework può essere installato tramite pip o Docker. Per l’installazione tramite pip:
Per l’installazione Docker, si possono utilizzare le immagini preconstruite su Docker Hub.
Preparazione dei Dati
LLaMA Factory supporta diversi formati di dati, tra cui dataset su Hugging Face, ModelScope o cloud storage. È possibile specificare il percorso dei dati direttamente nel codice.
Fine-Tuning
Il framework permette di eseguire il fine-tuning tramite CLI o interfaccia web. Ad esempio, per eseguire un fine-tuning con LoRA:
Modelli Vision-LLM: LLaVA-1.5, LLaVA-NeXT, LLaVA-NeXT-Video, InternVL, etc.
I dataset supportati includono:
Dataset per fine-tuning supervisionato: Alpaca, ShareGPT, etc.
Dataset per modellazione delle ricompense: Human Feedback, etc.
Dataset per compiti multimediali: ImageNet, COCO, etc.
Conclusione
LLaMA Factory rappresenta un passo avanti nella personalizzazione e ottimizzazione dei modelli linguistici. Con la sua capacità di unificare metodi, modelli e risorse, il framework si distingue come una soluzione versatile per sviluppatori, ricercatori e aziende. Che si tratti di addestrare un modello per un’applicazione specifica o di esplorare nuove tecnologie, LLaMA Factory offre strumenti potenti e accessibili.
Se sei interessato a esplorare le potenzialità di LLaMA Factory, visita il sito ufficiale o segui il blog per rimanere aggiornato sulle ultime novità e tutorial.
LLaMA Factory: perché il fine-tuning non deve mai essere complicato.
Nel mondo accelerato del web, dove la tecnologia cambia ogni giorno il modo in cui interagiamo con l’informazione, un tema sempre più rilevante è l’idea di “scrivere per l’AI”. Questo concetto, una volta considerato un’ipotesi futuristica, sta diventando una realtà concreta, trasformando radicalmente la scrittura umana e il suo scopo. Da un lato, l’Intelligenza Artificiale (AI) ha reso più accessibili e immediati i dati, permettendo a chiunque di ottenere informazioni in pochi secondi. Dall’altro, però, questa evoluzione ha portato a una profonda riflessione su come gli umani stanno adattando il loro lavoro, non più per gli esseri umani, ma per gli algoritmi che dominano il web.
La scrittura, una delle forme più antiche di comunicazione, sta subendo una metamorfosi. Non si tratta più solo di condividere idee o informazioni, ma di creare contenuti che siano “leggibili” e “comprensibili” per le macchine. Questo cambiamento non è solo tecnologico, ma anche culturale e sociale. Gli scrittori, i giornalisti, i creatori di contenuti e perfino i professionisti come i PR stanno riconoscendo che il loro lavoro deve adattarsi a nuove regole: quelle dell’AI.
L’evoluzione del web e il ruolo dell’AI Negli ultimi anni, il web è diventato un luogo dove l’informazione è accessibile a tutti, ma anche un ambiente in cui la competizione per l’attenzione è spietata. La nascita dei motori di ricerca come Google ha reso possibile trovare informazioni in pochi secondi, ma ha anche creato un sistema in cui i contenuti devono essere ottimizzati per essere visibili. Con l’avvento degli strumenti di intelligenza artificiale, come ChatGPT e Claude, questa dinamica sta cambiando. Gli algoritmi non solo “leggono” il web, ma lo “assimilano”, analizzando dati, creando risposte e persino influenzando il modo in cui le informazioni vengono condivise.
Questo ha portato a una nuova forma di scrittura: non più rivolta a un pubblico umano, ma a un sistema di intelligenza artificiale che, grazie al suo addestramento su milioni di testi, ha acquisito una capacità di comprensione e di generazione di contenuti. Perché, come sottolinea il magazine della Phi Beta Kappa, “l’idea di un mondo in cui gli umani scrivono, ma lo fanno principalmente per l’AI, è diventata una possibilità reale”.
Scrivere per l’AI: una strategia necessaria? Il fenomeno è stato ampiamente discusso da figure come Tyler Cowen, economista e influencer, che ha sottolineato come la scrittura per l’AI sia diventata una forma di “influenza” su un pubblico non umano. “Scrivere per l’AI non è solo una strategia per ottenere visibilità, ma un modo per influenzare il futuro”, ha dichiarato Cowen. La sua motivazione? Non solo aumentare il proprio impatto, ma anche “insegnare” agli algoritmi ciò che si ritiene importante.
Ma come si fa a scrivere per l’AI? La risposta è semplice: adattare il contenuto a come gli algoritmi “leggono” e “processano” l’informazione. Gli strumenti di intelligenza artificiale non solo analizzano testi, ma li “strutturano”, cercando informazioni chiare, dati organizzati e contenuti formattati. Per questo, la scrittura ottimizzata per l’AI richiede una struttura chiara, sezioni ben definite e una chiara espressione degli intenti.
Questo ha portato a una nuova forma di marketing e comunicazione: il “chatbot optimization” (CO). I professionisti del PR, sempre alla ricerca di influenze, stanno sviluppando strategie che non solo mirano a Google, ma a algoritmi come ChatGPT. La chiave per ottenere attenzione da parte dell’AI è scrivere in modo che sia “leggibile” per loro, con un linguaggio semplice, dati ben organizzati e un’organizzazione logica.
Tra opportunità e preoccupazioni Se da un lato l’AI offre nuove opportunità per la comunicazione e la diffusione delle idee, dall’altro solleva interrogativi su cosa possa significare per la creatività umana. Alcuni sottolineano che la scrittura per l’AI potrebbe portare a una perdita di valore umano, riducendo la scrittura a una mera forma di ottimizzazione per algoritmi. “L’AI legge tutto, mentre gli umani non leggono quasi nulla”, ha commentato un utente, riferendosi al fatto che l’AI è in grado di analizzare ogni tipo di contenuto, mentre la maggior parte delle persone si limita a leggere solo ciò che è necessario.
Altri, invece, vedono in questo cambiamento un modo per immortaliare la propria voce. “Scrivere per l’AI potrebbe essere la chiave per un’immortalità intellettuale”, ha affermato un commentatore, sottolineando che gli algoritmi potrebbero “riconoscere” e “valorizzare” i contenuti che rientrano nei loro parametri di qualità. Tuttavia, molti sottolineano che l’AI non è in grado di comprendere le emozioni, le esperienze umane o il contesto culturale, rendendo la scrittura per l’AI un’attività limitata.
Le critiche e le sfide Nonostante i pro e i contro, il dibattito intorno alla scrittura per l’AI è stato accompagnato da critiche e preoccupazioni. Alcuni sottolineano i limiti tecnologici degli algoritmi, che non sono in grado di comprendere il significato profondo di un testo, ma solo di generare risposte basate su dati. “L’AI non è in grado di distinguere tra informazioni utili e inutili, né di valutare il valore di un contenuto”, ha scritto un commentatore, sottolineando il rischio di “informazione di scarsa qualità” che potrebbe proliferare.
Altri, invece, si concentrano sulle implicazioni etiche e sociali. “Scrivere per l’AI potrebbe portare a una dipendenza tecnologica, riducendo la capacità degli umani di pensare criticamente”, ha affermato un utente, preoccupato che l’uso crescente di algoritmi possa influenzare la capacità di valutare fonti e verificare fatti. Questo tema è particolarmente rilevante in un’epoca in cui il web è pieno di informazioni spesso inaffidabili, e l’AI potrebbe amplificare questa problematica.
Un futuro in bilico tra innovazione e conservazione L’evoluzione della scrittura per l’AI rappresenta un punto di svolta nella comunicazione digitale. Da un lato, offre nuove opportunità per diffondere idee e informazioni in modo più efficiente. Dall’altro, solleva domande fondamentali su cosa significhi essere umani in un mondo dominato da algoritmi.
Sebbene alcuni vedano in questo cambiamento un’opportunità per l’immortalità intellettuale, altri temono la perdita di valore umano e la riduzione della scrittura a una mera forma di ottimizzazione. La sfida, quindi, è trovare un equilibrio tra innovazione e conservazione, tra l’uso delle tecnologie e la protezione della creatività umana.
Conclusione La scrittura per l’AI è un fenomeno che sta trasformando il modo in cui gli umani comunicano e condividono informazioni. Sebbene il tema sia ancora in fase di evoluzione, è chiaro che il ruolo degli algoritmi nel web non è più un’ipotesi futuristica, ma una realtà che richiede adattamento e riflessione. Per chiunque si trovi a scrivere oggi, la domanda rimane: come si può preparare il proprio lavoro per un pubblico che non è più umano?
Nella sua semplicità è il bot (gestito da un workflow N8N) che uso più spesso. I messaggi vocali sono lenti e inefficienti, l’accelerazione 1.5x o 2x risolve solo in parte il problema. Poter leggere velocemente, o scansionare, il contenuto di un vocale senza dover essere bloccato due minuti per ascoltarlo tutto è una fantastica comodità.
Ho migliorare un pochettino il workflow per gestire correttamente anche l’inoltro, sempre tramite telegram, di una MP3. Il motivo scatenante è stato che non volevo ascoltare un podcast di un ora per una piccola frazione di informazione, durata 5 minuti, annegata chissà dove.
Ho per cui modificato la gestione dell’input, cambiato i timeout di risposta, e gestito l’output di più di 2000 caratteri con lo stesso sistema del bot assistente personale.
Per trascrivere un ora di podcast l’hardware a mia disposizione ha impiegato 22 minuti, ma va bene. Non avevo fretta. E’ comunque una velocità superiore al doppio e mentre il silicio lavorava io potevo fare altro.
Il punto di partenza è stato quanto descritto in questo articolo. Il bot è sempre disponibile pubblicamente su http://t.me/b0sh8_bot anche se non tutti i giorni e non H24.
L’intelligenza artificiale (IA) ha trasformato il modo in cui le aziende elaborano informazioni. Ma i modelli linguistici di grandi dimensioni (LLM) spesso mancano di conoscenza aggiornata e possono generare dati errati. La tecnica di retrieval‑augmented generation (RAG) unisce ricerca documentale e generazione, riducendo le allucinazioni e mantenendo il modello aggiornato. Quando questa metodologia è abbinata a sistemi agentici intelligenti che decidono autonomamente quale strumento utilizzare, nasce l’agentic RAG, una nuova frontiera che migliora la precisione e la trasparenza delle risposte. Il modello di decision‑tree guida la logica decisionale in questi sistemi, consentendo una pianificazione adattiva basata su test successivi. In questo articolo esploreremo passo dopo passo queste tecnologie, partendo dalla base dell’IA, passando per RAG, l’agent AI, l’agentic RAG e infine il ruolo del decision tree.
Capire l’Intelligenza Artificiale: Fondamenti e Sfide
Il settore dell’Intelligenza Artificiale (IA) è nato con l’obiettivo di replicare l’intelligenza umana nei sistemi computazionali. I primi sistemi basati su regole rigide e approcci simbolici si sono dimostrati difficili da scalare e poco robusti di fronte alla variabilità dei dati reali. Con l’avvento dei modelli di apprendimento profondo, l’IA ha guadagnato capacità di estrazione di pattern non lineari, portando allo sviluppo dei cosiddetti Large Language Models (LLM). Tuttavia, i LLM pur essendo potenti, soffrono di allucinazioni, mancano di spiegabilità e richiedono enormi risorse computazionali. Per mitigare tali problemi, la ricerca ha intensificato lo studio di architetture decision‑tree, che suddividono il processo decisionale in nodi specializzati (es. ricerca, sintesi, filtro). Tale modularità consente un tracciamento chiaro delle operazioni, facilita la gestione degli errori e permette di combinare modelli leggeri per la routing con LLM pesanti per il ragionamento approfondito. Inoltre, le decision‑trees favoriscono l’apprendimento continuo grazie alla possibilità di aggiungere nuovi “tool” in modo incrementale. In sintesi, l’evoluzione dall’IA tradizionale a sistemi decision‑tree‑augmented rappresenta un passo cruciale verso soluzioni più efficienti, trasparenti e sostenibili. Gli approcci decision‑tree non solo migliorano la qualità delle risposte, ma permettono anche una gestione più fine delle risorse di calcolo, poiché il carico computazionale viene distribuito tra componenti di diverso peso. Ciò riduce l’overhead di addestramento e facilita l’implementazione su infrastrutture esistenti, rendendo l’IA più accessibile e adattabile a scenari reali.
Retrieval‑Augmented Generation (RAG): La Nuova Frontiera per LLM
RAG è un’architettura che combina la ricerca di informazioni (retrieval) con la generazione di testo (augmentation). In pratica, un modello di linguaggio chiama un sistema di ricerca vettoriale per recuperare documenti pertinenti, quindi integra questi documenti nel proprio prompt per produrre risposte basate su fonti verificabili. Questo approccio riduce le allucinazioni, perché la generazione è ancorata a dati esterni, e migliora la precisione senza richiedere un costoso fine‑tuning del modello principale.
Agent AI: Sistemi Intelligenti che Operano in Ambienti Dinamici
I chatbot tradizionali si basano principalmente sulla risposta a prompt testuali. Con gli agenti AI, l’interazione diventa autonoma e contestuale: il sistema valuta lo stato attuale, decide quale azione compiere (ricerca, sintesi, visualizzazione) e produce la risposta in modo iterativo.
In un contesto Retrieval‑Augmented Generation (RAG), l’agente accede in tempo reale a una base di conoscenza, recupera i documenti più rilevanti e poi genera la risposta con un modello LLM, integrando così recupero e generazione in un’unica pipeline decisionale.
L’implementazione di Elysia si basa su un “decision tree orchestrato” dove ogni nodo è un tool (retriever, summariser, visualizzatore, ecc.). Il decision agent valuta il contesto, la storia delle interazioni e i costi computazionali per scegliere l’operazione più adatta. Questo approccio garantisce trasparenza: il percorso decisionale è visibile in tempo reale, facilitando debug e audit.
Per le imprese, i vantaggi sono:
– Affidabilità migliorata grazie alla gestione degli errori e ai limiti di iterazione.
– Riduzione dei costi di sviluppo: i componenti possono essere riutilizzati senza riformulare prompt.
– Personalizzazione pro‑attiva che apprende dai feedback degli utenti.
Il futuro prevede l’integrazione di agenti multi‑modalità, la capacità di autogenerare nuovi tool e la sinergia con sistemi di controllo decisionale complessi, aprendo la strada a soluzioni enterprise completamente autonome.
Agentic RAG e Decision Tree: La Logica Decisionale dei Sistemi
Elysia sfrutta una decision‑tree architecture per coordinare gli agenti. Ogni nodo è un tool specifico—retriever, LLM, visualizer—e la scelta di quale nodo attivare avviene tramite un decision agent che valuta contestualmente i dati, i risultati precedenti e le potenziali ramificazioni future. Questo modello si ispira alle teorie dei Decision Trees, dove la struttura ad albero rappresenta una sequenza di test decisionali, ognuno dei quali conduce a ulteriori sotto‑decisioni o a un risultato finale. In Elysia, i test sono adaptivi: l’agente ricalcola le probabilità di successo di ciascun branch in base ai feedback in tempo reale, spostando dinamicamente l’albero verso percorsi più promettenti. La profondità dell’albero è limitata da un hard pass limit che evita loop infiniti; al superamento di questo valore, l’agente propaga un errore verso un percorso alternativo o invia una notifica di fallimento.
Flusso decisionale in una lista:
Input utente → nodo di analisi preliminare
Test di compatibilità del dato → scegliere retriever o preprocessore
Chiamata LLM → valutare qualità della risposta
Se insufficiente, ricalcolo: attivare visualizer o iterare con nuovo prompt
Output finale → rendering dinamico e memorizzazione preferenza utente
Esempi pratici:
Nel negozio di skincare, il percorso dall’input di un problema cutaneo al consiglio di prodotto passa da un retriever di documenti, a un LLM di sintesi, fino a un visualizer di carte prodotto.
In un sistema di raccomandazione, la decision tree genera una serie di filtri di prodotto, crea una collezione di articoli correlati e poi genera un prompt per l’LLM che propone prodotti finali.
Conclusioni
Il futuro dell’IA non è solo potenza di calcolo, ma capacità di integrare conoscenza esterna in modo intelligente e decisionale. RAG, quando combinato con architetture agentiche e modelli di decision‑tree, offre soluzioni più affidabili, trasparenti e adattabili. Le imprese possono ora sfruttare data‑driven chat‑bots e agenti autonomi che si evolvono con il loro ambiente, riducendo il rischio di allucinazioni e garantendo la citazione delle fonti.
Link di partenza per la generazione del testo : https://weaviate.io/blog/elysia-agentic-rag La generazione e’ stata fatta con GPT-OSS 20B, che per arrivare all’articolo di cui sopra (circa 1000 parole, 500 token) ha prodotto 50.000 token in elaborazioni successive, tra cui riassunto a pezzi con metodo map-reduce, pianificazione dell’articolo interrogando anche altre fonti (wikipedia) e redazione dei singoli capitoli. Proverò comunque Elysia e magari scriverò qualcosa anche io direttamente.