Quanto segue e’ la traduzione di Build a LOCAL AI Coding Assistant: Qwen3 + Ollama + Continue.dev (Blazing Fast & Fully Private!) … non ho ancora provato il setup ma son molto curioso e lo faro’ a breve.
Volevo condividere il mio percorso nell’utilizzare diversi assistenti AI per la programmazione — da GitHub Copilot a Cursor e ora a Windsurf — e come infine ho trovato il punto ideale passando a una soluzione completamente locale, senza compromettere velocità o qualità 🔥.
Vediamo insieme come ci sono arrivato:
💡 L’evoluzione del mio stack AI per la programmazione
- GitHub Copilot : Buon inizio, ma contesto limitato e non molto profondo.
- Cursor : Un notevole balzo in termini di potenza e flessibilità, specialmente grazie a Cursor Composer.
- Windsurf : Wow, questa mi ha impressionato! La sua capacità di indiciare e comprendere le basi di codice è eccezionale. Non è necessario dargli a conoscere i file da analizzare — semplicemente sa . Dai un’occhiata a lukalibre.org — interamente costruito con Windsurf 🤯Ma… c’è sempre un problema.
🛑 Il problema: Costo, velocità e limiti 😤
- Windsurf costa 20 dollari al mese — prezzo equo per ciò che offre.
- MA… ti limita a 500 crediti al mese, e la modalità di pensiero di Claude 3.7 utilizza 1,5 volte per ogni chiamata .
- Anche pagando, a volte è lento ⏳.
- Stessa storia con Cursor e Copilot.
- E non iniziamo nemmeno a parlare delle preoccupazioni per la privacy dei dati — se la tua azienda non permette strumenti esterni, sei bloccato.
🚨 L’ingresso: Ollama + Continue.dev
Avevo pensato:
“Cosa succederebbe se potessi eseguire modelli potenti in locale?”
Così ho provato:
- Ollama : Ospita LLM in locale (idea fantastica).
- Continue.dev : Offre un’esperienza simile a quella di Cursor/Windsurf.
MA…
- Modelli come Llama3 o Mistral non erano proprio all’altezza.
- Sono pesanti e lenti sui laptop 💻➡️🐢
✨ Poi arrivò Qwen3: Alert di cambiamento di gioco 🎯💥
Ecco dove le cose si fecero veramente interessanti.
Qwen3 (soprattutto la variante 30b-a3b) mi ha lasciato a bocca aperta!
- Utilizza distillazione + Mixture-of-Experts (MoE) → inferenza estremamente veloce.
- Nonostante sia un modello da 30B, vengono utilizzati solo 3B di parametri per ogni prompt 🚀.
- Le prestazioni? Strabiliantemente vicine a quelle di giganti come Claude 3.7 Sonnet e GPT-4o.
- Funziona senza problemi su un laptop decente — testato su: i7 + RTX 2070Mac M4 Max
E il meglio di tutto: Nessuna perdita di dati, nessuna chiave API, nessuna attesa.
📌 Passo passo: Come impostare Qwen3 localmente con Continue.dev (Mac & Windows) 🖥️🛠️
Facciamolo insieme:
✅ Passo 1: Installare Ollama
Mac :
brew install ollama
Windows : Scaricare da: ollama.com/download
Avviare Ollama dopo l’installazione.
✅ Passo 2: Scaricare Qwen3 e modello di embedding
Nel terminale o in PowerShell:
ollama pull qwen3:30b-a3b
ollama pull nomic-embed-text
Perché questi modelli?
- qwen3:30b-a3b: Il cervello principale AI 🧠 (gestisce chat, completamento automatico, modifiche).
- nomic-embed-text: Aiuta l’AI a comprendere l’intera base di codice (spiegato di seguito ⬇️).
✅ Passo 3: Installare l’estensione Continue.dev in VS Code
- Apri VS Code.
- Vai alle Estensioni (icona 🔍 nel lato sinistro).
- Cerca “Continue”.
- Clicca su Installa.
✅ Passo 4: Configurare Continue per utilizzare Qwen3
- In VS Code, vai alla scheda Continue (icona 🧠).
- Clicca sull’icona ingranaggio ⚙️ > Apri Configurazione.
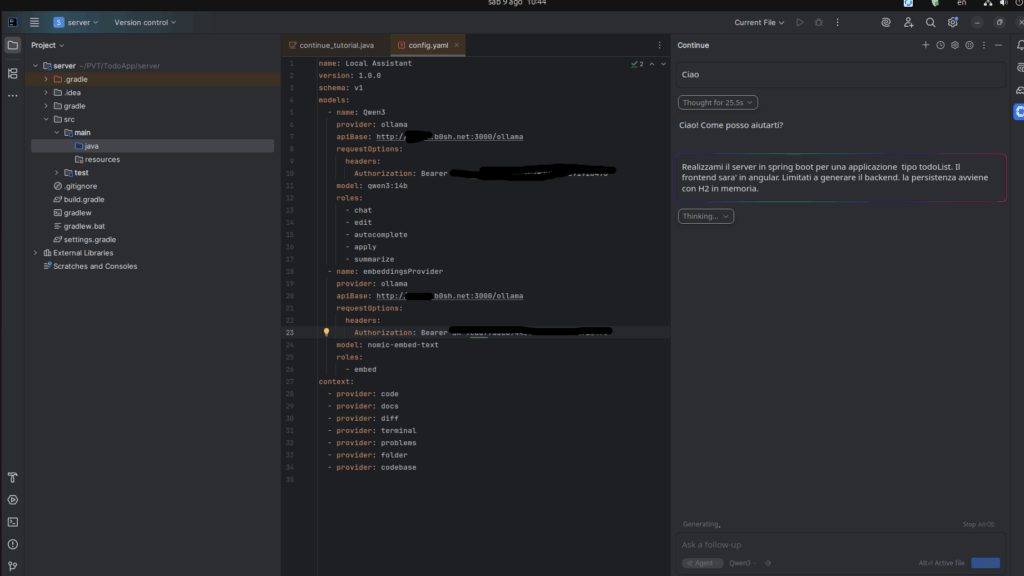
- Sostituisci la configurazione predefinita con questa:
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Qwen3-30b
provider: ollama
model: qwen3:30b-a3b
roles:
- chat
- edit
- autocomplete
- apply
- summarize
- name: embeddingsProvider
provider: ollama
model: nomic-embed-text
roles:
- embed
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
🔍 Cosa fa ogni parte del YAML
models:
Definisce i “cervelli” del tuo assistente.
- Qwen3–30b
- embeddingsProvider
context:
Dichiara a cosa può accedere l’AI quando risolve problemi:
- codice: File corrente.
- docs: Documentazione (come i README).
- diff: Cambiamenti Git.
- terminal: Output del terminale (per il debug).
- problems: Errori del linter.
- folder: Cartella intera del progetto.
- codebase: Indice completo della base di codice (grazie al modello di embedding!).
Senza questo, il tuo assistente vedrebbe solo il file che stai modificando — come cercare di riparare un motore di un’auto senza vedere l’intera auto 🚗.
✅ Passo 5: Finito! 🎉
Ora hai un assistente AI per la programmazione locale che è:
- 🔒 Privato (nessuna perdita di dati)
- ⚡ Veloce (eseguito sul tuo computer)
- 💪 Potente (si confronta con GPT-4o/Claude 3.7)
- 🌐 Pronto per l’offline
📌 Pensieri finali
Se sei stanco di pagare per token limitati, risposte lente o vuoi il pieno controllo sul tuo codice e i tuoi dati, prova Qwen3 + Ollama + Continue.dev.
È stato un cambiamento di gioco per me 🧠✨, e spero che ti aiuti anche tu.