In questo articolo, esploreremo il ruolo chiave dell’intelligenza artificiale, N8N, i workflow, l’agentic AI e i modelli linguistici di grandi dimensioni (LLM) nel contesto tecnologico moderno. Questi argomenti rappresentano una combinazione potente che sta rivoluzionando il modo in cui sviluppiamo e utilizziamo le applicazioni.
Introduzione all’Intelligenza Artificiale e n8n
L’intelligenza artificiale (AI) sta trasformando il modo in cui creiamo e gestiamo i flussi di lavoro, e uno strumento che sta guadagnando attenzione è n8n. Questo strumento permette di costruire workflow complessi in modo visivo e intuitivo, integrando facilmente API e servizi esterni. Con l’avvento dell’Agentic AI, i workflow possono diventare autonomi, prendendo decisioni basate su dati e feedback in tempo reale. L’uso di LLM (Large Language Models) all’interno di questi workflow apre nuove possibilità, come l’analisi del testo, la generazione di contenuti e l’automazione intelligente. Questa combinazione di tecnologie promette di semplificare processi complessi, aumentando l’efficienza e riducendo il carico umano.
Intelligenza Artificiale e Workflow Dinamici
L’intelligenza artificiale (AI) sta rivoluzionando il modo in cui creiamo e gestiamo i workflow, grazie ad strumenti come n8n, una piattaforma open source che permette di costruire e automatizzare processi complessi. Con l’introduzione di agentic AI, i workflow non sono più semplici sequenze di istruzioni, ma diventano dinamici e adattivi, grazie all’uso di LLM (Large Language Models) che possono prendere decisioni autonome. Questo approccio consente di creare soluzioni personalizzate, scalabili e in grado di evolversi nel tempo.
L’intelligenza artificiale (AI) rappresenta una delle tecnologie più promettenti del nostro tempo
L’intelligenza artificiale (AI) rappresenta una delle tecnologie più promettenti del nostro tempo, con applicazioni che vanno dall’automazione al riconoscimento delle immagini. Uno strumento chiave per sfruttare al massimo le potenzialità dell’AI è n8n, una piattaforma open source che permette di creare workflow complessi senza la necessità di codificare. Questo strumento è particolarmente utile quando si lavora con l’AI agente, dove un modello linguistico di grandi dimensioni (LLM) esegue compiti autonomi e interagisce con altri sistemi. Il potere di n8n risiede nella sua capacità di integrare diversi strumenti e API, rendendo il processo di sviluppo più fluido e accessibile.
L’intelligenza artificiale (AI) sta trasformando il modo in cui creiamo e gestiamo i workflow
grazie a strumenti come n8n, una piattaforma open source che permette di collegare diversi servizi e applicazioni in modo semplice e intuitivo. In combinazione con l’AI, n8n permette di automatizzare compiti complessi, riducendo il tempo e gli errori umani. L’agente AI, un sistema autonomo in grado di prendere decisioni, può essere integrato nei workflow per eseguire compiti specifici, come l’analisi dei dati o la generazione di testi, grazie all’uso di modelli linguistici di grandi dimensioni (LLM). Questa sinergia tra AI, n8n, workflow e agente AI rappresenta un passo avanti significativo nell’automazione intelligente.
Conclusioni
L’AI, N8N, i workflow, l’agentic AI e i LLM stanno aprendo nuove possibilità nel mondo della tecnologia. Questi strumenti, quando utilizzati insieme, possono portare a un’evoluzione significativa in molti settori, rendendo il software più intelligente, personalizzato e adattabile.
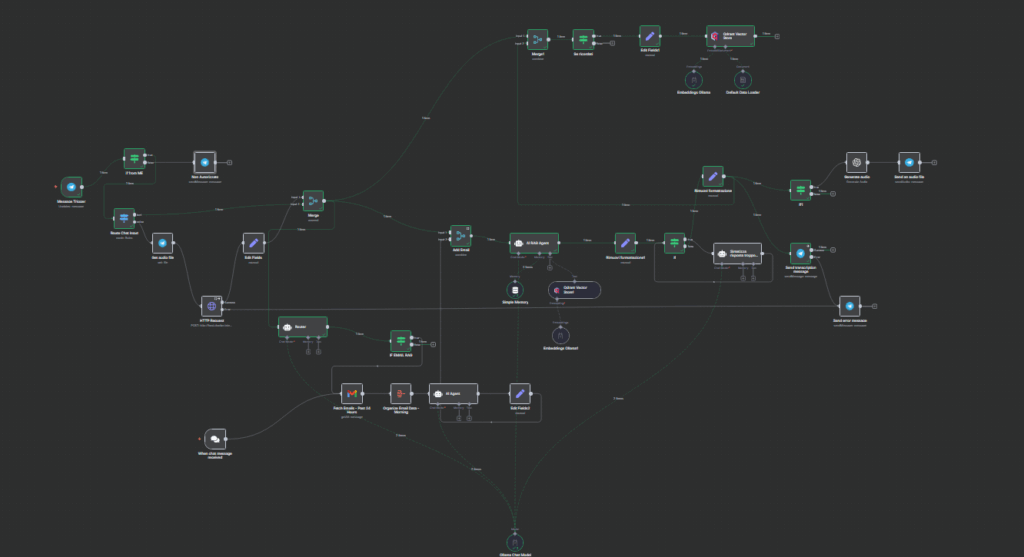
Questo articolo, fin qua, e’ stato interamente scritto tramite AI e un workflow N8N, che a partire da un elenco di keyword ha generato il testo e pubblicato (in bozza) sul sito. Mi sono ispirato ad un workflow reso disponibile pubblicamente e modificato, come al solito, per usare ollama e per scrivere in italiano. L’idea e’ di adattarlo ulteriormente per partire da un testo o ancora meglio da una pagina web che mi ha interessato per generare un post, invece che dalle keyword. Se ne esce qualcosa di interessante pubblicherò il risultato.